
Vision par ordinateur
La vision par ordinateur est devenue un pilier de nombreuses applications modernes, de la reconnaissance d’images à l’analyse médicale en passant par la conduite autonome. Grâce à des plateformes comme Hugging Face, il est aujourd’hui plus facile que jamais d’accéder à des modèles de vision performants et de les adapter à ses propres besoins. Dans cet article, nous explorerons quelques modèles de vision populaires disponibles sur Hugging Face, puis nous verrons pas à pas comment affiner (fine-tuner) un modèle Vision Transformer (ViT) à l’aide de Google Colab, sans nécessiter d’infrastructure coûteuse.
Modèles de vision sur Hugging Face
Hugging Face s’est imposée comme une plateforme incontournable dans l’écosystème de l’intelligence artificielle en rendant les modèles de machine learning accessibles, partageables et reproductibles. Au-delà du traitement du langage naturel pour lequel elle est initialement connue, la plateforme héberge aujourd’hui une vaste collection de modèles de vision par ordinateur prêts à l’emploi. On y trouve notamment des Vision Transformers (ViT), des modèles de classification d’images, de détection d’objets, de segmentation, de reconnaissance faciale et même des modèles multimodaux comme CLIP ou DINO. Grâce au Hub, à l’API Inference et aux Spaces interactifs, Hugging Face permet non seulement d’explorer ces modèles rapidement dans le navigateur, mais aussi de les réutiliser et de les affiner pour des cas d’usage concrets, ce qui en fait un point central pour quiconque travaille avec des modèles de vision.
Échantillon de modèles de vision
Segmentation par langage naturel

Retrait du fond de l’image

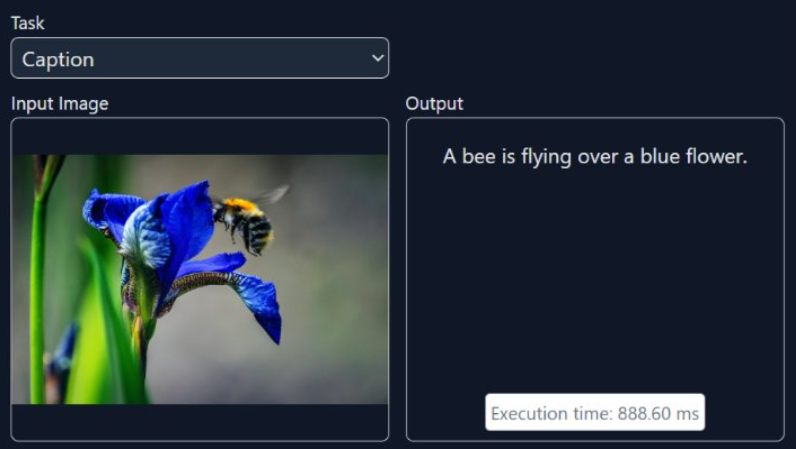
Génération d’une description de l’image
Segmentation et dénombrement de cellules

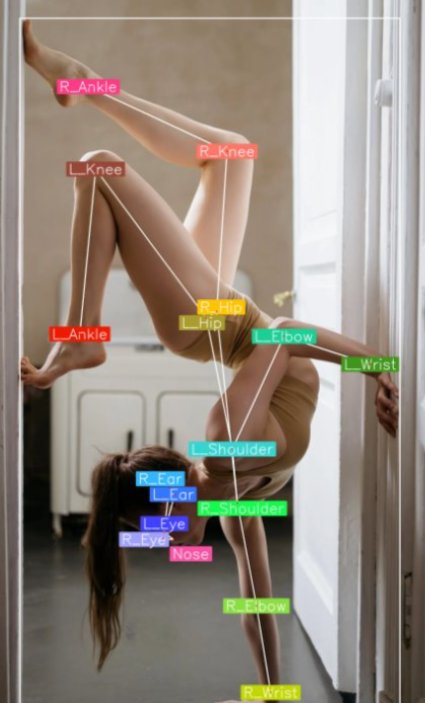
Identification du positionnement du corps
Autres modèles de vision sur Hugging Face
Identification des caractères
Estimation de la pose
Détection de visages
Exercice d’exploration

Affinage d’un modèle dans Colab
Google Colab est un environnement de notebooks Python gratuit et hébergé dans le cloud qui permet d’exécuter du code sans avoir à configurer sa propre machine, tout en offrant un accès facile à des ressources GPU. Très prisé par la communauté d’apprentissage machine, il facilite l’expérimentation, le partage et la reproduction d’analyses grâce à une interface interactive basée sur Jupyter.
Dans la suite de cet article, nous utiliserons Google Colab pour réaliser un exercice pratique d’affinage (fine-tuning) d’un modèle de vision en Python.
Plus précisément, nous adapterons un modèle Vision Transformer à la tâche de classification d’images en nous appuyant sur le jeu de données Oxford Flowers 102, qui contient 102 catégories de fleurs et constitue un excellent cas d’étude pour apprendre à spécialiser un modèle préentraîné sur une tâche réelle.
Lien vers le code Colab
https://colab.research.google.com/drive/1dgMH9LIkJXg0NsYzC-12GwnIKqHRLeMi?usp=sharing
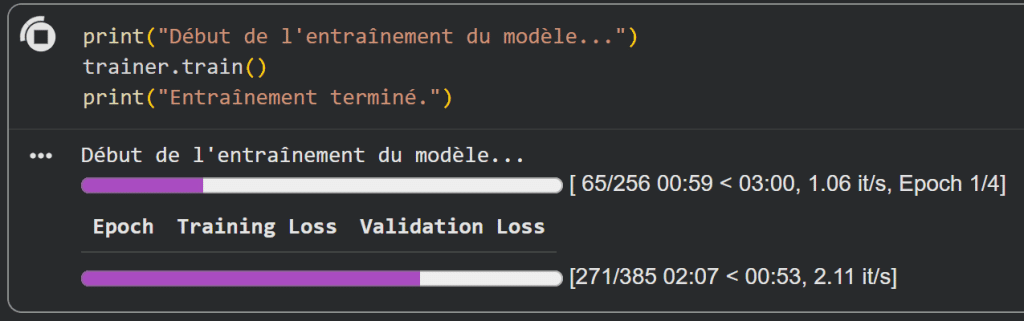
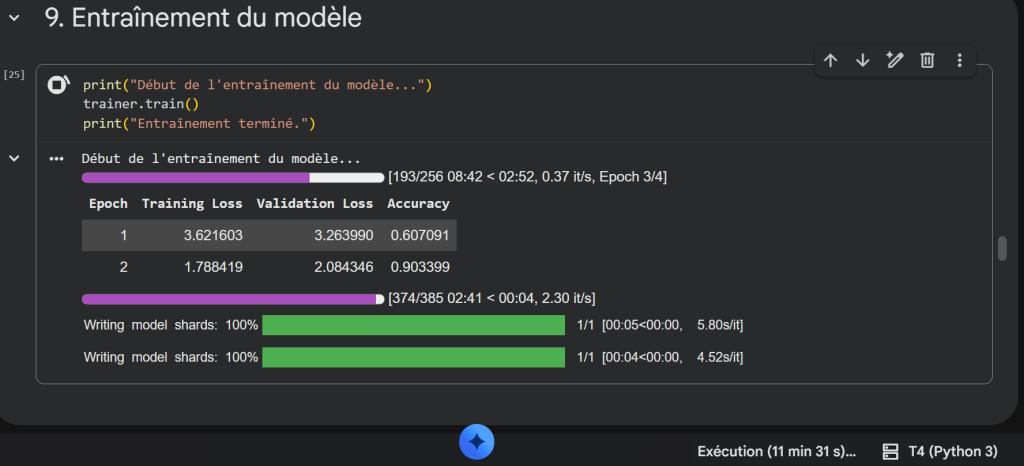
Pour en savoir plus sur le code, lisez cet article :
L’affinage (fine-tune) des modèles d’IA expliqué avec les fleurs