
Affinage d’un modèle
L’intelligence artificielle ne se limite plus à reconnaître des chiffres manuscrits ou à générer du texte. Aujourd’hui, elle sait distinguer une tulipe d’une marguerite, un chat d’un tigre… à condition d’avoir bien été entraînée ! Plongeons dans les bases de l’entraînement et de l’affinage (fine-tune), en prenant un cas concret : la détection de fleurs.
Pourquoi entraîner un modèle ?
Un modèle d’IA, au départ, ne sait rien. Il doit apprendre à partir de données : des images, du texte, du son… Ce processus d’apprentissage consiste à ajuster les paramètres internes du modèle pour qu’il puisse généraliser ce qu’il voit.
Exemple : si on montre à un modèle 10 000 photos de fleurs, il finira par repérer des motifs (couleurs, formes, textures) qui lui permettront de reconnaître de nouvelles fleurs jamais vues.
L’affinage (fine-tune), c’est quoi ?
Former un modèle à partir de zéro (from scratch) demande souvent des centaines de milliers d’images et des semaines de calcul. L’affinage (fine-tune) consiste à partir d’un modèle déjà pré entraîné sur un grand ensemble d’images (comme ImageNet) et à le spécialiser sur notre tâche précise : ici, la reconnaissance de fleurs.
Imaginez que le modèle de départ sache déjà détecter des formes, des pétales, des tiges… Il suffit de lui apprendre à associer ces formes à un type de fleur : rose, tulipe, lys, etc. Résultat : moins de données, moins de calculs, mais des performances impressionnantes !
CPU, GPU ou TPU ?
Tout ce calcul ne se fait pas n’importe où. Voici les trois grandes familles de processeurs utilisés :
- CPU (Central Processing Unit)
C’est le processeur classique de votre ordinateur. Il sait tout faire, mais lentement quand il s’agit d’IA. - GPU (Graphics Processing Unit)
Pensé à l’origine pour les jeux vidéo, le GPU excelle dans les calculs parallèles. En IA, il permet d’entraîner un modèle 10 à 100 fois plus vite qu’un CPU. - TPU (Tensor Processing Unit)
Créé par Google, ce processeur est spécialement optimisé pour les réseaux de neurones. On le retrouve surtout sur Google Colab ou dans les infrastructures cloud de Google.
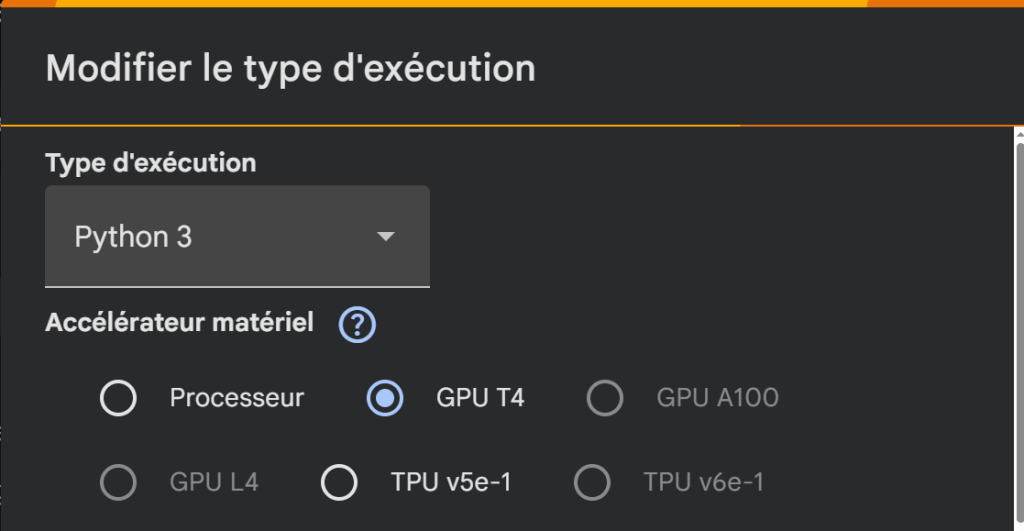
💡 Sur Colab, on peut choisir Exécution → Modifier le type d’exécution → GPU pour accélérer l’affinage.
Le cas des fleurs 🌼
Dans notre exemple, nous utilisons le jeu de données Oxford Flowers 102, qui contient 102 espèces de fleurs, chacune illustrée par plusieurs dizaines de photos. Le modèle de base choisi est ViT (Vision Transformer), développé par Google. C’est un modèle d’architecture transformer, semblable à ceux utilisés pour le texte (comme BERT), mais appliqué aux images.
Notre but : partir du modèle vit-base-patch16-224 (déjà entraîné sur des millions d’images) et l’affiner pour qu’il distingue les 102 types de fleurs.
Les bibliothèques utiles 🧰
Pour ce projet, plusieurs outils collaborent :
- Transformers : pour charger, configurer et entraîner le modèle.
- Datasets : pour télécharger et manipuler facilement les jeux de données.
- Torch / PyTorch : le moteur mathématique derrière tout le calcul.
- Gradio : pour créer une interface web interactive et tester notre modèle en glissant une image.
- Accelerate : pour simplifier la gestion du GPU et la performance.
⚙️ Hyperparamètres essentiels
Lorsqu’on entraîne un modèle, certains réglages ont un impact majeur :
- learning rate (taux d’apprentissage) : contrôle la vitesse à laquelle le modèle apprend. Trop élevé ? Il diverge. Trop bas ? Il n’apprend pas.
- batch size : nombre d’images traitées à la fois.
- epochs : nombre de fois que le modèle voit l’ensemble des données.
- weight decay : empêche le modèle de « trop coller » aux exemples d’entraînement (surapprentissage).
- data augmentation : modifications légères (rotation, zoom, symétrie) appliquées aux images pour rendre le modèle plus robuste.
Configuration typique
Pour l’affinage du modèle ViT sur les fleurs, une configuration simple pourrait être :
epochs = 3learning_rate = 5e-5batch_size = 8warmup_ratio = 0.1weight_decay = 0.01fp16 = True(entraînement en précision réduite pour accélérer sur GPU)
Ces valeurs suffisent pour un bon compromis entre temps d’entraînement et précision.
Ce que le modèle apprend réellement
Au fil de l’entraînement, le modèle ajuste ses poids internes pour reconnaître :
- des formes globales (rondeur, pétales, centre)
- des textures (veloutées, lisses, rugueuses)
- des couleurs dominantes
- et même le contexte (feuilles, arrière-plan, lumière)
C’est un peu comme si un étudiant observait des milliers de photos et finissait par « voir » les différences entre chaque fleur.
Et ensuite ?
Une fois l’affinage terminé, on peut sauvegarder le modèle et le charger dans Gradio pour tester : on glisse une photo de tulipe, et le modèle répond : tulipa — probabilité : 0.98 🌷
Prêt à coder ? Votre premier pas dans l’affinage de modèle !
Vous avez maintenant les bases pour comprendre comment entraîner et fine-tuner un modèle d’IA. Le meilleur moyen d’apprendre, c’est de pratiquer !
J’ai préparé un notebook Google Colab complet qui met en œuvre tout ce que nous avons discuté. Vous pourrez y exécuter le code, fine-tuner un modèle pour reconnaître les fleurs, et même téléverser vos propres images pour voir le modèle en action !
🌐Pour aller plus loin
- 📘 Cours introductif sur PyTorch
- 📗 Guide du fine-tuning sur Hugging Face
- 📙 Tutoriel Google Colab sur ViT
- 📒 Dataset Oxford Flowers sur Kaggle
Apprendre à affiner un modèle, c’est comme apprendre à jardiner : il faut de bonnes graines (les données), un terreau fertile (le modèle de base), et un peu de patience pour voir les fleurs pousser… dans la mémoire du GPU ! 🌻
Code Python pour Colab
Ce lien vous permet de télécharger le code et de le copier dans Colab.
Bonne expérimentation !
Résultats de l’entrainement
| Indicateur | Valeur | Interprétation |
|---|---|---|
| Perte (eval_loss) | 2.6255 | Mesure à quel point le modèle se trompe encore. Plus elle est faible, mieux c’est. |
| Précision (eval_accuracy) | 0.8401 → 84.0 % | 84 % des images de fleurs du jeu de validation sont bien classées. C’est une très bonne performance pour un modèle entraîné seulement 3 époques. |
| Durée d’évaluation (eval_runtime) | 128 s | Temps total pour évaluer le modèle sur les données de validation. |
| Échantillons par seconde (eval_samples_per_second) | 47.9 | Le modèle traite environ 48 images par seconde pendant la validation. |
| Époques (epoch) | 3.0 | L’ensemble des données a été parcouru trois fois pendant l’entraînement. |
Les coûts cachés de la puissance de calcul
L’entraînement et le fine-tuning de modèles d’IA, même pour des tâches en apparence modestes, reposent sur une infrastructure informatique gourmande :
- Consommation énergétique massive : les GPU (processeurs graphiques) et les TPU (Tensor Processing Units) sont des bêtes de calcul, mais ils consomment énormément d’énergie. Les serveurs qui les hébergent, ainsi que les centres de données qui les regroupent, nécessitent une alimentation électrique constante et des systèmes de refroidissement intenses. Cette énergie provient souvent de sources non renouvelables, contribuant aux émissions de gaz à effet de serre.
- Ressources minières et déforestation : la fabrication de ces composants électroniques (GPU, puces, câbles) exige l’extraction de ressources minières précieuses, parfois rares, dont l’extraction a un impact direct sur les écosystèmes (déforestation, pollution des sols et de l’eau).
- Impact climatique : l’ensemble de ce cycle, de l’extraction des matières premières à la consommation électrique des serveurs,
contribue à l’empreinte carbone globale de l’IA, participant ainsi au changement climatique.
- Pour notre exemple de fine-tuning pour la reconnaissance de fleurs, nous avons :
- Téléchargé plus de 2 Go de données (le jeu de données oxford_flowers102 et le modèle ViT pré-entraîné). Chaque gigaoctet transféré sur le réseau a un coût énergétique.
- Effectué un entraînement d’environ 15 minutes sur un GPU (via Google Colab). Même cette courte période représente une consommation d’énergie significative par rapport à une tâche informatique classique. Bien que ces chiffres puissent sembler faibles individuellement, imaginez l’échelle lorsque des milliers de chercheurs et d’entreprises entraînent des modèles encore plus grands, pendant des jours ou des semaines, sur des centaines de GPU.
Vers une IA plus responsable
Il ne s’agit pas de renoncer à l’IA, mais d’en prendre conscience et d’agir de manière plus responsable :
- Optimisation des modèles : préférer des modèles plus petits et plus efficaces lorsque c’est possible (comme DistilBERT ou des
versions « Tiny » de ViT). - Optimisation de l’entraînement : réduire le nombre d’époques, utiliser des techniques de fine-tuning efficaces, et optimiser les hyperparamètres pour minimiser le temps de calcul.
- Infrastructures vertes : encourager l’utilisation de centres de données alimentés par des énergies renouvelables.
- Réutilisation : maximiser l’utilisation des modèles pré-entraînés et du fine-tuning pour éviter de ré-entraîner des modèles de zéro inutilement. L’IA est un outil puissant, mais comme tout outil, son utilisation doit être réfléchie et consciente de ses conséquences. En tant que futurs acteurs de ce domaine, vous avez un rôle crucial à jouer pour construire une IA plus durable. Est-ce possible?